Computer Vision – next generation
It is more than 2 years since I wrote the article regarding object detection using OpenCV https://technobium.com/object-detection-with-opencv/ and by the number of comments and emails I get, I see that the subject is still interesting. For those in search for an object detection solutions I thought to prepare a small update on the topic. Under evaluation we will have three platforms that offer object detection APIs: Microsoft, IBM and Google.
The evaluation approach will be the following: we will have two images, that will be processed on each platform. The first image is a pretty straightforward one, Scarlett Johansson.

The second one, is a bit more complicated: Barack Obama meeting Dalai Lama. 
We will see what can each API say about the images and how fast will the processing be.
Microsoft Cognitive Services – Computer Vision API
https://www.microsoft.com/cognitive-services/en-us/computer-vision-api
So, ladies first, we will start with the image of Scarlett on the Microsoft platform. Load time: 3.5 seconds. Results are to be seen bellow.
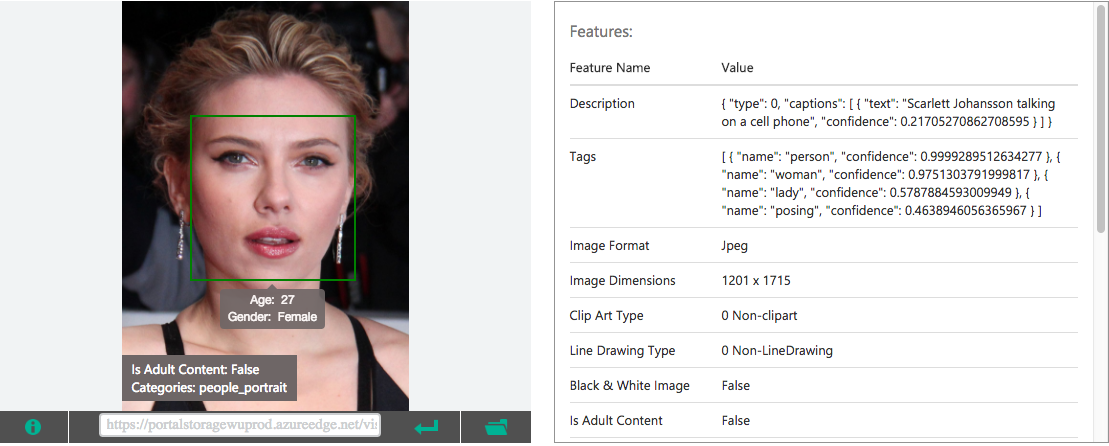
The Microsoft API could detect the face, the gender, the age 27 years and the fact that this is a person’s portrait. If we take into consideration that the picture was taken February 2012, and Scarlett was born November 1984, that gives us 27 year the real age. Pretty impressive! The description seems a little funny: “Scarlett Johansson talking on a cell phone” with a low confidence – 0.2. The important thing to notice here is that it detected the name of the celebrity. Next, there are some tags with higher confidence like: “person”, “woman”, “lady” and “posing”.
Moving on, to the important meeting. Load time: 2.36 seconds.
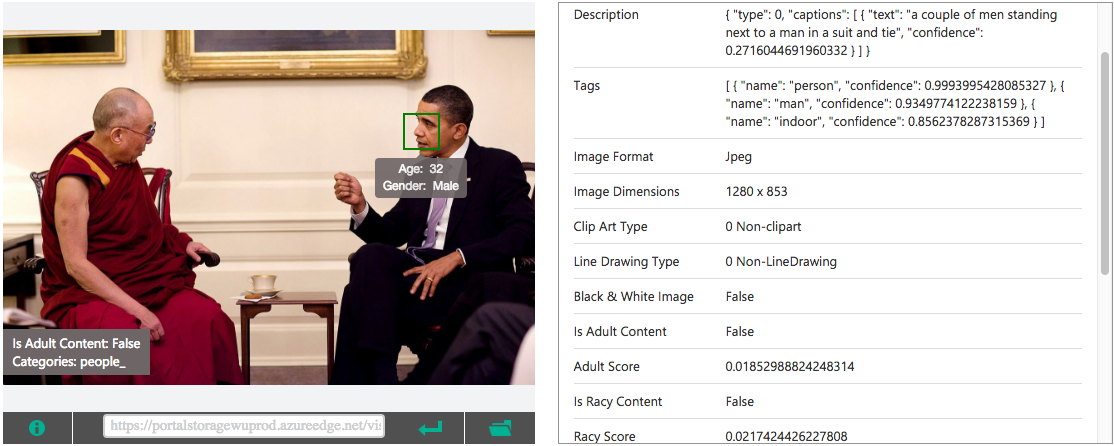
For the second image, the Microsoft API detects the fact that in the picture there are people. The description is half true: “A couple of men standing next to a man in a suit and a tie”, low confidence. Other than that, it finds the tags: “person”, “man”, “indoor”. The only face detected is the one of Barack Obama. According to the algorithm, the age is 32, which obviously false. But it looks kind of young in that picture. I presume if I didn’t knew him I would have given him a similar age. Adult and racial content detection works well in this case as you can see in the low scores.
IBM Watson Developer Cloud – Visual Recognition
https://visual-recognition-demo.mybluemix.net/
Let’s ask Watson what he sees in the first picture. Load time: 7.8 seconds
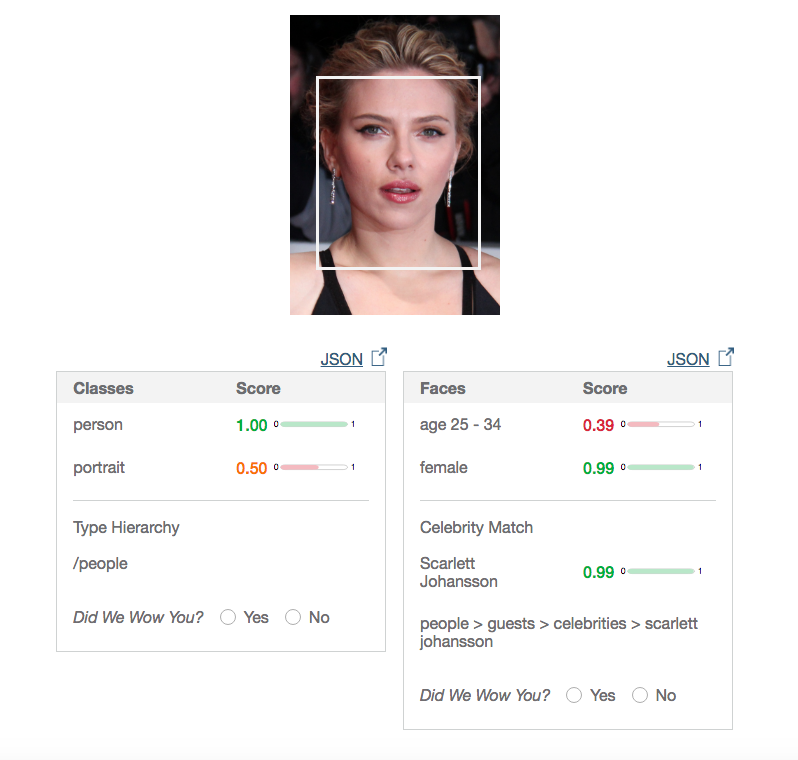
He identifies the face, the fact that it is a person and that the age is between 25 an 34 year. This with a 39% confidence. Watson is pretty sure that in the image we have a woman and that woman is Scarlett Johansson. The information is offered also in JSON format, to be consumed directly by third party applications.
Let’s ask now Watson what he sees in the second picture. Load time: 6.94 seconds.
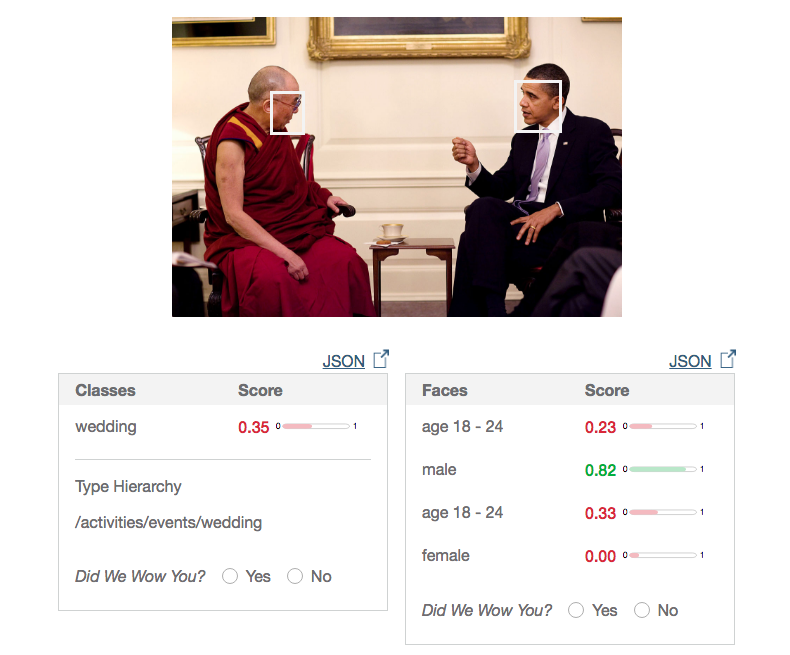
The good thing here is that it detects both faces, even if Dalai Lama is not facing the camera. Watson seems to be having a good sense of humour because he gives a 35% chances, that the picture is taken at a wedding. For a person he gives a high confidence (82%) for being a man and for the other person has 0% confidence for being a female. For the age interval 18-24 he gives low confidence levels, 23% and 33%.
Google Cloud Platform – Vision API
https://cloud.google.com/vision/
Let’s start the testing on the Google Cloud Platform and see what does their algorithm detect in the first picture. Load time: 3.7 seconds.
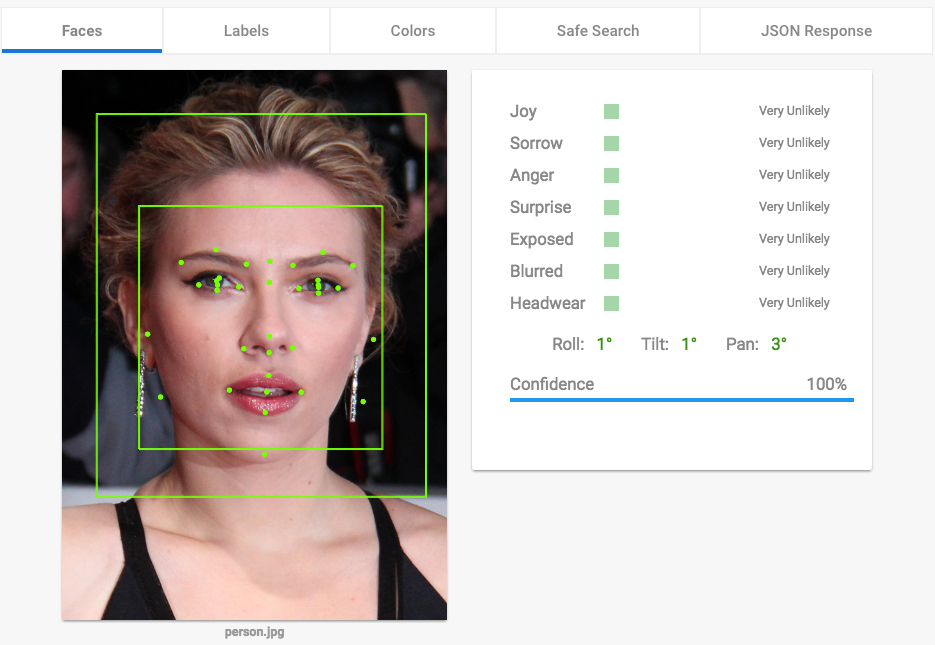
Google detects the face, the main points on the face and does a sentiment analysis. The sentiment analysis for this particular image has a with very low confidence level. As labels it detects: “hair”, “face”, “eyebrow”, “hairstyle”, “nose”, “beauty”, “head”, “brown hair”, “fashion”, “super model”, “layered hair”, “long hair”, “model”, “hair”.
Now the picture with the high level meeting. Loading time: 1.95 seconds.
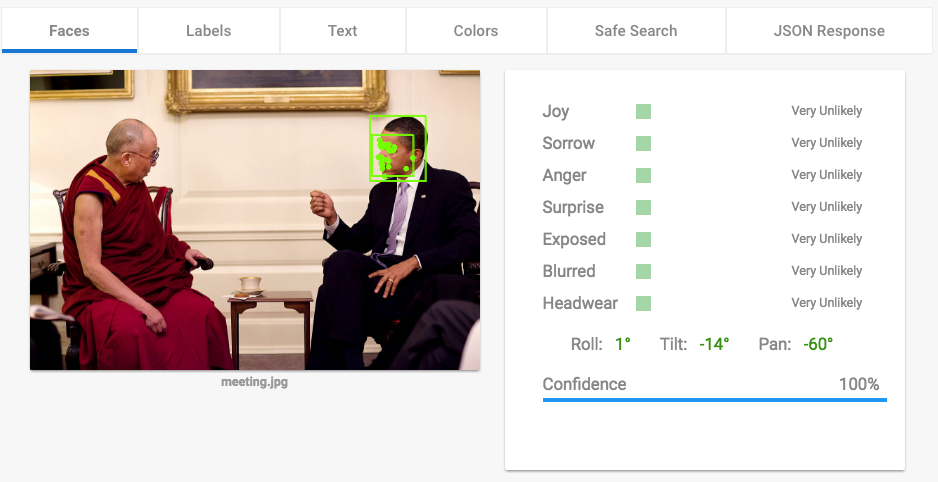
The only face detected is the one of Barack Obama, Dalai Lama is not detected in this case. Also the confidence for the sentiment analysis is low. As labels the following are detected: “person”, “people”, “conversation”, “ceremony”, “ritual”. The clothing of Dalai Lama guided the result towards ceremony and ritual. The safe search section offers adult, spoof, medical and violence detection. For this particular image the safe search gave good results, meaning that there is no adult, spoof, medical or violence related content in it.
Conclusion
The computer vision APIs are evolved but still not 100% accurate. I cannot declare a clear winner, you should choose depending on the needs of your software solution. Feel free to try them, the demos are available free online.
A remarkable thing though: each of the three platforms needed more time to process the image of a woman, compared to the image of two men – see the numbers. The conclusion is clear in my opinion, even computer find it hard to understand women. Artificial Intelligence won’t solve this problem 🙂
