Reinforcement learning – Q Learning Java
Ever wondered how a robot could learn something by itself? The short answer is: reinforcement learning. This is the third major machine learning algorithms class, next to supervised learning and unsupervised learning. The basic idea behind reinforcement learning is that the software agent learns which action to take, based on a reward and penalty mechanism. The learner is not told which actions to take, as in most forms of machine learning, but instead must discover which actions yield the most reward by trying them. Simply put: carrots and sticks 🙂
A basic algorithm which can demonstrate easily the reinforcement learning concepts is Q Learning. In the following sections we will explore the algorithm and its Java implementation. The code for the article is written using Java 8 and can be found here: https://github.com/technobium/q-learning-java
Q Learning algorithm
Let’s imagine a light seeking robot that must navigate from room to room in order to stop in the brightest room. See below the map of the rooms. We can consider it a maze through which our light-seeking robot will need to navigate. The rooms are numbered from 0 to 8 to be easily identified further in the Java implementation of the algorithm.
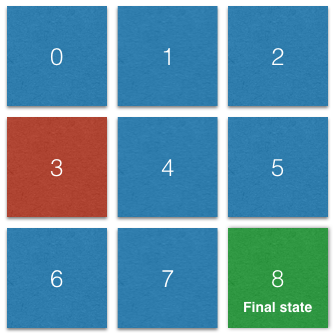
Each room can be considered a state (S), moving from one room to another is considered an action (A). For simplification the robot can move one room at a time, left, right up or down. The algorithm will need a reward matrix R and will output a quantity matrix Q.
The matrix R contains for each state a row with the following encodings:
- -1 for the impossible transitions. For example from 0 to 0 we have -1. From 0 to 4 we cannot navigate directly, so we have here also -1. The same is for the navigation from 0 to 8.
- 0 for possible transitions. For example we can go from 0 to 1, so we will have 0 in the matrix row 0 column 1. Another example, we can navigate directly from 4 to 7, row 4 column 7 is 0.
- 100 is the reward for the final state (the brightest room). We can navigate from 5 to 8 so the reward matrix has in row 5 column 8 the value 100. The same situation for row 7 column 8.
- -10 is the penalty (suppose we had a room with lower light intensity compared to the other rooms). As you can see, we can reach room 3 from room 0, 4 and 6. For that reason, column 0 row 3 has value -10 and the same for row 4 column 3 and row 6 column 3.
States: 0 1 2 3 4 5 6 7 8 Possible states from 0 :[ -1 0 -1 -10 -1 -1 -1 -1 -1] Possible states from 1 :[ 0 -1 0 -1 0 -1 -1 -1 -1] Possible states from 2 :[ -1 0 -1 -1 -1 0 -1 -1 -1] Possible states from 3 :[ 0 -1 -1 -1 0 -1 0 -1 -1] Possible states from 4 :[ -1 0 -1 -10 -1 0 -1 0 -1] Possible states from 5 :[ -1 -1 0 -1 0 -1 -1 -1 100] Possible states from 6 :[ -1 -1 -1 -10 -1 -1 -1 0 -1] Possible states from 7 :[ -1 -1 -1 -1 0 -1 0 -1 100] Possible states from 8 :[ -1 -1 -1 -1 -1 -1 -1 -1 -1]
Now the Q matrix is filled in by the following algorithm:
For each training cycle:
Select a random initial state.
Do While the final state has not been reached.
Select one among all possible actions for the current state.
Using this possible action, consider going to the next state.
Get maximum Q value for this next state based on all possible actions.
Compute Q: Q(state,action)= Q(state,action) + alpha * (R(state,action) + gamma * Max(next state, all actions) – Q(state,action))
Set the next state as the current state.
End Do
End For
You may have noticed two factors alpha and gamma.
Alpha is the learning rate. The learning rate determines to what extent the newly acquired information will override the old information. A factor of 0 will make the agent not learn anything, while a factor of 1 would make the agent consider only the most recent information. In our implementation we will use a constant learning rate of 0.1.
Gamma is the discount factor and determines the importance of future rewards. A factor of 0 will make the agent “myopic” (or short-sighted) by only considering current rewards, while a factor approaching 1 will make it strive for a long-term high reward. In our implementation we will use a discount factor of 0.9.
After building the Q matrix, we can use it as follows:
- start from a given initial state
- from that state select the action with the highest Q value
- set the current state to the next state (reached by following the action with the highest Q)
- repeat until the final state is reached
In the Java algorithm you will see that we print the optimal path starting from each state.
Java implementation of Q learning
The code that implements the Q learning algorithm can be found here: https://github.com/technobium/q-learning-java.
The init() function loads the maze map from a .txt file and builds the R matrix, in concordance with the rules described in the previous section. The convention is that the final state is marked with the character ‘F’, the possible states are marked with the character ‘0’ (zero) and the states penalty states are marked with the character ‘X’ . Here is how the maze file should look like
0 0 0 X 0 0 0 0 F
In the constants sections you can configure the maze dimensions, the alpha and gamma parameters and also the reward and penalty values:
private final double alpha = 0.1; // Learning rate
private final double gamma = 0.9; // Eagerness - 0 looks in the near future, 1 looks in the distant future
private final int mazeWidth = 3;
private final int mazeHeight = 3;
private final int statesCount = mazeHeight * mazeWidth;
private final int reward = 100;
private final int penalty = -10;
The main function here is the one that builds the Q matrix. It follows the steps described in the previous section.
void calculateQ() {
Random rand = new Random();
for (int i = 0; i < 1000; i++) { // Train cycles
// Select a random initial state
int crtState = rand.nextInt(statesCount);
while (!isFinalState(crtState)) {
int[] actionsFromCurrentState = possibleActionsFromState(crtState);
// Pick a random action from the ones possible
int index = rand.nextInt(actionsFromCurrentState.length);
int nextState = actionsFromCurrentState[index];
// Q(state,action)= Q(state,action) + alpha * (R(state,action) + gamma * Max(next state, all actions) - Q(state,action))
double q = Q[crtState][nextState];
double maxQ = maxQ(nextState);
int r = R[crtState][nextState];
double value = q + alpha * (r + gamma * maxQ - q);
Q[crtState][nextState] = value;
crtState = nextState;
}
}
}
After the Q matrix is calculated we can use it and print the optimal route from each initial state:
void printPolicy() {
System.out.println("\nPrint policy");
for (int i = 0; i < statesCount; i++) {
System.out.println("From state " + i + " goto state " + getPolicyFromState(i));
}
}
int getPolicyFromState(int state) {
int[] actionsFromState = possibleActionsFromState(state);
double maxValue = Double.MIN_VALUE;
int policyGotoState = state;
// Pick to move to the state that has the maximum Q value
for (int nextState : actionsFromState) {
double value = Q[state][nextState];
if (value > maxValue) {
maxValue = value;
policyGotoState = nextState;
}
}
return policyGotoState;
}
For this particular example here are the results you should get:
Q matrix From state 0: 0.00 72.90 0.00 62.90 0.00 0.00 0.00 0.00 0.00 From state 1: 65.61 0.00 81.00 0.00 81.00 0.00 0.00 0.00 0.00 From state 2: 0.00 72.90 0.00 0.00 0.00 90.00 0.00 0.00 0.00 From state 3: 65.61 0.00 0.00 0.00 81.00 0.00 81.00 0.00 0.00 From state 4: 0.00 72.90 0.00 62.90 0.00 90.00 0.00 90.00 0.00 From state 5: 0.00 0.00 81.00 0.00 81.00 0.00 0.00 0.00 100.00 From state 6: 0.00 0.00 0.00 62.90 0.00 0.00 0.00 90.00 0.00 From state 7: 0.00 0.00 0.00 0.00 81.00 0.00 81.00 0.00 100.00 From state 8: 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 Print policy From state 0 goto state 1 From state 1 goto state 2 From state 2 goto state 5 From state 3 goto state 4 From state 4 goto state 5 From state 5 goto state 8 From state 6 goto state 7 From state 7 goto state 8 From state 8 goto state 8
As you can see, the software agent has learnt how to build his way to the final state, only by giving him rewards for the actions taken. You can experiment with the algorithm by changing the maze and the parameters.
Conclusion
The current article is a simple introduction to the reinforcement learning fields. It is an extremely interesting field that is related with other disciplines, like game theory, control theory, operations research, information theory, simulation-based optimization, multi-agent systems, swarm intelligence,statistics, and genetic algorithms.
A short note on the importance of this algorithm: a recent application of Q-learning to deep learning, by Google DeepMind, titled “deep reinforcement learning” or “deep Q-networks”, has been successful at playing some Atari 2600 games at expert human levels.
References
https://en.wikipedia.org/wiki/Q-learning
double maxQ = maxQ(nextState);
when nextState is the final state this returns -Infinity.
The q matrix becomes:
From state 0: 0.00 0.00 0.00 -10.00 0.00 0.00 0.00 0.00 0.00
From state 1: 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
From state 2: 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
From state 3: 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
From state 4: 0.00 0.00 0.00 -10.00 0.00 0.00 0.00 0.00 0.00
From state 5: 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 NaN
From state 6: 0.00 0.00 0.00 -10.00 0.00 0.00 0.00 0.00 0.00
From state 7: 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 NaN
From state 8: 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
There is a problem in the maxQ(…) method –
double maxValue = Double.NEGATIVE_INFINITY;
should be:
double maxValue = 0;
If you make this change, then you get the Q matrix shown above…
Is this code really working ? When I copy paste it does not work .. Even that one in GitHub
Hi,
The code needs to be compiled with Java 1.8 and should work. I updated the pom.xml on GitHub to force Java 1.8 compilation and the code is working fine.
git clone https://github.com/technobium/q-learning-java.gitmvn clean compile exec:java -Dexec.mainClass="com.technobium.rl.QLearning"
Best Regards,
Leo
git clone https://github.com/technobium/q-learning-java.git
not checkout