A glimpse into SyntaxNet – the world’s most accurate parser
Spring 2016 Google released SyntaxNet as an open source project. Big news! But what is this? This is a syntactic parser that has behind a neural network written on TensorFlow – an open source software library for numerical computation using data flow graphs. A syntactic parser is a software component that takes as input a text and returns the same text enriched with part-of-speech (POS) tags. For Natural Language Understanding (NLU) problems, a POS tagger helps understanding the syntactic function of each word and the syntactic relationship between the words in a sentence.
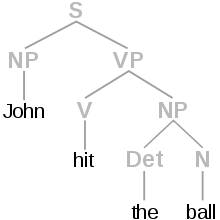
Let’s say you want to build a chat bot. In order for the system to really understand the human input, it first need to understand the meaning of the input. This is where a NLU and more precisely a POS tagger is needed.
The SyntaxNet project includes the code needed to train SyntaxNet models on your own data, as well as Parsey McParseface, an English parser. For those interested to test the English parser you can follow this nice article http://www.whycouch.com/2016/07/how-to-install-and-use-syntaxnet-and.html.
If you want to work with other languages, you can train your model on using the data from Universal Dependencies project. This is also a very interesting project contains annotated training data for the following languages:
- Ancient Greek
- Arabic
- Basque
- Bulgarian
- Catalan
- Chinese
- Croatian
- Czech
- Danish
- Dutch
- English
- Estonian
- Finnish
- French
- Galician
- German
- Gothic
- Greek
- Hebrew
- Hindi
- Hungarian
- Indonesian
- Irish
- Italian
- Kazakh
- Latin
- Latvian
- Norwegian
- Old_Church_Slavonic
- Persian
- Polish
- Portuguese
- Portuguese-BR (Brazilian Portugese)
- Romanian
- Russian
- Slovenian
- Spanish
- Swedish
- Tamil
- Turkish
German POS Tagger
The following steps will guide you trough the setup of a SyntaxNet instance, so that you can decide for yourself if this is the world’s most accurate parser. For the current example I used German, but you can use any of the languages supported by Universal Dependencies.
Prerequisites: install Docker on Ubuntu (kernel equal or higher than 3.10)
sudo apt-get install docker.io
Preparing the Docker image. This may take a while, depending on your machine.
mkdir build cd build wget https://raw.githubusercontent.com/tensorflow/models/master/syntaxnet/Dockerfile sudo docker build -t syntaxnet .
Run the newly created image:
docker run -i syntaxnet bash
You should be now in the bash command mode on the Docker image. Run the following commands:
mkdir models cd models curl -O http://download.tensorflow.org/models/parsey_universal/German.zip unzip German.zip export MODEL_DIRECTORY=/opt/tensorflow/models/syntaxnet/models/German cd .. echo "Ich bin ein Berliner." | syntaxnet/models/parsey_universal/parse.sh $MODEL_DIRECTORY
The output should be something linke this:
1 Ich _ PRON _ fPOS=PRON++ 4 nsubj _ _ 2 bin _ VERB _ fPOS=VERB++ 4 cop _ _ 3 ein _ DET _ fPOS=DET++ 4 det _ _ 4 Berliner. _ NOUN _ fPOS=NOUN++ 0 ROOT _ _
Enjoy POS tagging your preferred language and share your experience 🙂
Reference
https://research.googleblog.com/2016/05/announcing-syntaxnet-worlds-most.html
http://www.whycouch.com/2016/07/how-to-install-and-use-syntaxnet-and.html
http://universaldependencies.org/



Did you have to do anything apart from these steps?
Thanks